将文档存储到某个shard(Routing a Document to a Shard)
当我们新建一个文档时,ES是如何知道将它保存在哪个primary shard里呢?
这里有一个计算公式:
shard = hash(routing) % number_of_primary_shards
routing的值默认是文档的_id值,也可以手动设置。最终得到的shard编号介于0到number_of_primary_shards - 1之间。
应用场景:手动设置routing的值,将属于某个用户的文档都存放在同一个shard里面。
分布式搜索原理
分布式搜索包括两个步骤:查询(Query)和取回(Fetch)。
以如下请求为例:
GET /_search
{
"from": 90,
"size": 10
}
查询阶段
主要是在各个分片上执行搜索,并将结果返回给协调节点。
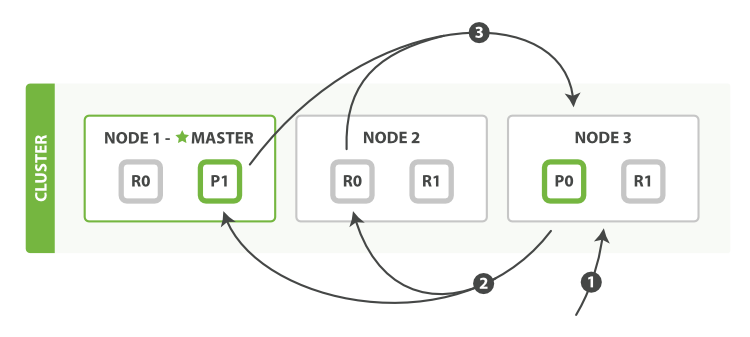
1) 客户端发送搜索请求给NODE3,NODE3会创建一个长度为from+size的空优先级队列.
2) NODE3转发这个搜索请求到索引中的每个分片(主分片或副本分片),每一个分片都会在本地执行请求,并将结果保存到一个长度为from+size的优先级队列。
3)每一个分片将文档的ID以及该文档在本地优先级队列中的排序值返回给协调节点NODE3(注意这一步并非返回完整文档),NODE3会把这些值合并到总的优先级队列里产生全局的排序结果(类似归并排序)。
取回阶段
既然在第一步中我们已经在协调节点NODE3里建立起了全局优先队列,那么下一步就是要取出真正的文档内容。
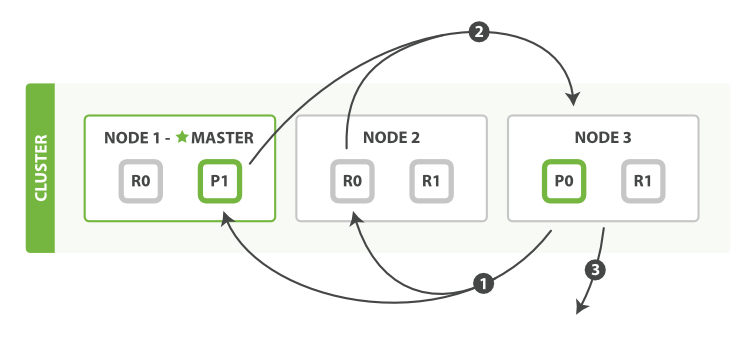
1) 协调节点NODE3判断哪些文档需要被取回,并发送GET请求到相关的shard。
2)每个收到GET请求的shard会加载文档内容并将其返回给协调节点NODE3。
3)当NODE3获取到了所有shard返回的文档后,NODE3将它们合并成最终的结果集,返回给客户端。