倒排索引
ES使用倒排索引来加速全文检索。一个倒排索引由两部分组成:在文档中出现的所有不同的词以及对每个词,它所出现的文档的列表。例如:如果我们有两个文档,每一个文档有一个content字段,包含的内容如下:
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
要创建一个倒排索引,首先要将文本内容分割成一个个单独的词,然后罗列每一个词出现的文档。此过程称为tokenization。
之后,将这些词条进行标准化操作,如大写变成小写,去掉没用的词a、and、the,同义词转换等等。此过程称为normalization。
tokenization和normalization统称为analysis,ES里提供了标准的分析器来实现分析操作。
经过分析后倒排索引建立如下:
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
------------------------
当倒排索引被加载进内存后,就会一直存在。只要内存空间足够大,所有的读操作就都是在内存中进行,速度之快可想而知。
索引更新机制
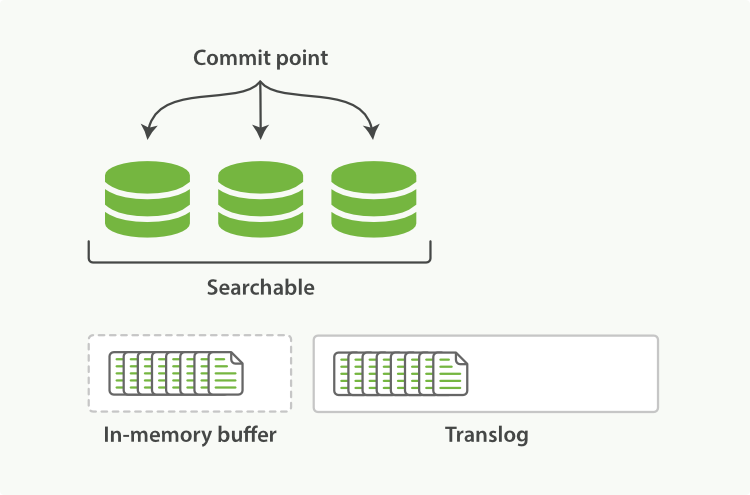
(1)新增的文档被提交到in-memory buffer,Transaction log会同步记下所有ES的操作
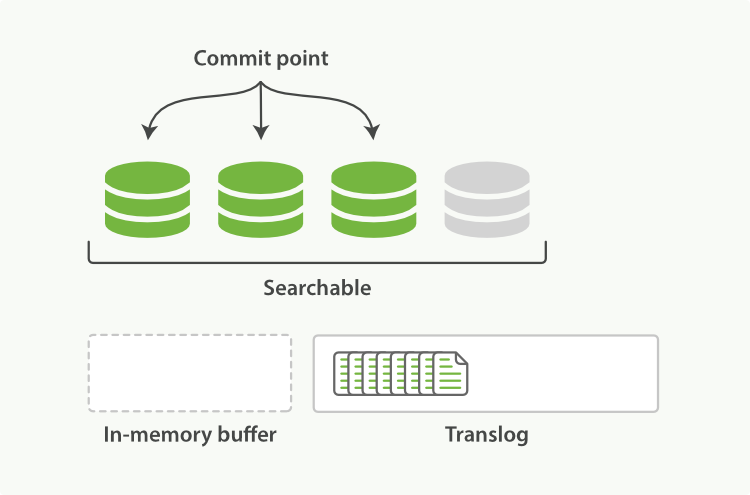
(2)in-memory buffer里的文档被refresh进新的segment,注意,此时新增的文档已经可以被搜索到,但仍在内存里还没持久化到磁盘中。
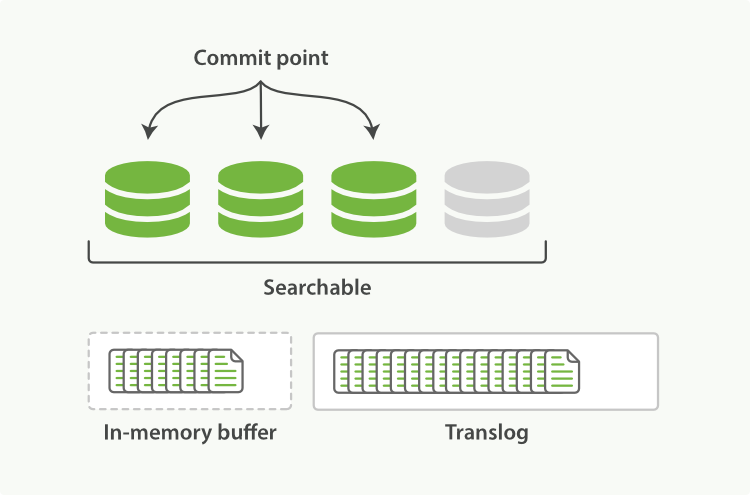
(3)不断有新文档提交,Transaction log文件越来越大
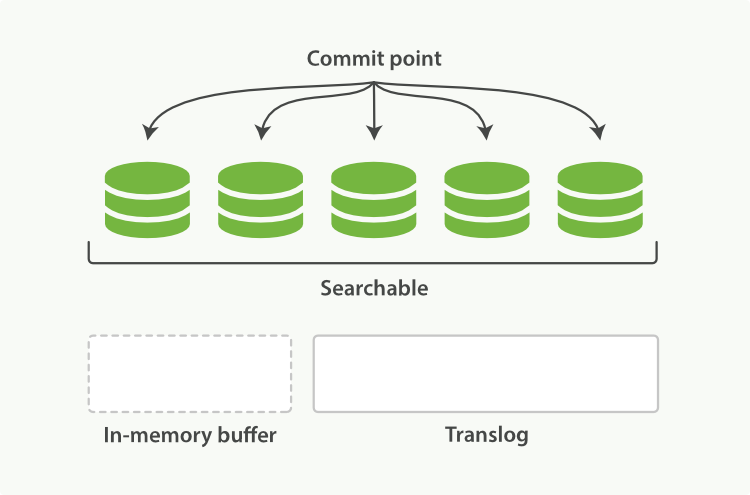
(4)进行flush操作也就是将数据写进磁盘,新的segment被记录进commit point,删除旧的translog,生成新的translog,清空in-memory buffer。
文档删除与修改
每一个segment都是不可变的,所以一旦有文档被删除时,segment是无法同步进行修改的。
事实上,我们在ES里删除文档时并非真正删除,而是将其标记为deleted。每一个commit point都包含一个.del文件,文件里标记着哪些文档被删除以及对应所处的segment。在进行检索时,依然会检索到被删除的文档,不过会在结果返回时被过滤掉。
文档更新同理,旧的文档被标记为deleted,新版本的文档会被放到新的segment里面。在检索时新旧文档可能同时匹配,但是旧的文档会被过滤出结果集。
segment merging
每一次Refresh操作都会新建一个segment,不需要多久,segment就会越积越多。每一个segment都会消耗掉内存和cpu资源,且segment越多,ES的检索速度越慢。为了解决这种情况,ES会在后台不断地进行segment的合并,将小的segment复制并合并成大的segment。对于那些老的标记为删除的segment将会被清除(文档真正被删除),且不会被合并到新的segment里。
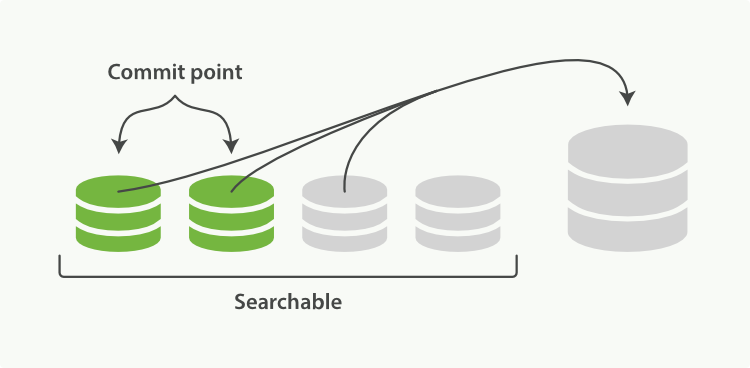
segment merging完成,新的segment被flush写入磁盘。
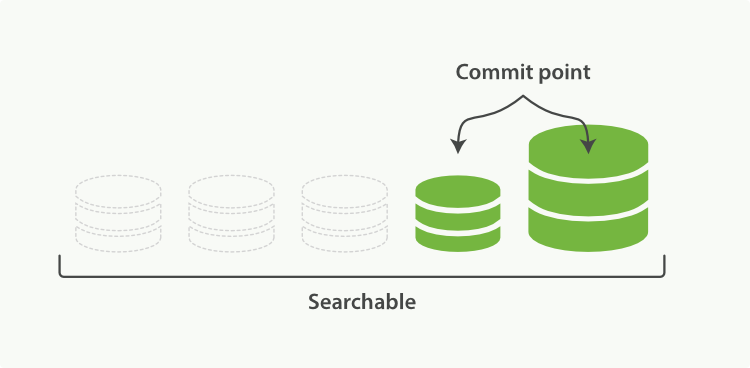
两个文件
(1)Commit point:a file that lists all known segments
(2)Translog:The translog provides a persistent record of all operations that have not yet been flushed to disk. When
starting up, Elasticsearch will use the last commit point to recover known segments from disk, and will then replay all
operations in the translog to add the changes that happened after the last commit. The translog is also used to provide real-
time CRUD. When you try to retrieve, update, or delete a document by ID, it first checks the translog for any recent changes
before trying to retrieve the document from the relevant segment. This means that it always has access to the latest known
version of the document, in real-time.
三个关键操作Refresh、Flush、Segment Merging
触发时机
- Refresh:默认每秒进行一次
- Flush:默认每30分钟或当translog大于512MB
- Segment Merging:官网上并没明确说明进行时机,摘抄下原话:It happens automatically while you are indexing and searching. (这里面涉及到参数的调整,参考文章)
为什么说ES的搜索时近实时(Near Real-time)
Elasticsearch has near real-time search: document changes are not visible to search immediately, but will become visible within 1 second (refresh every minute).
参考
Inverted Index
Translog
Inside a Shard